






















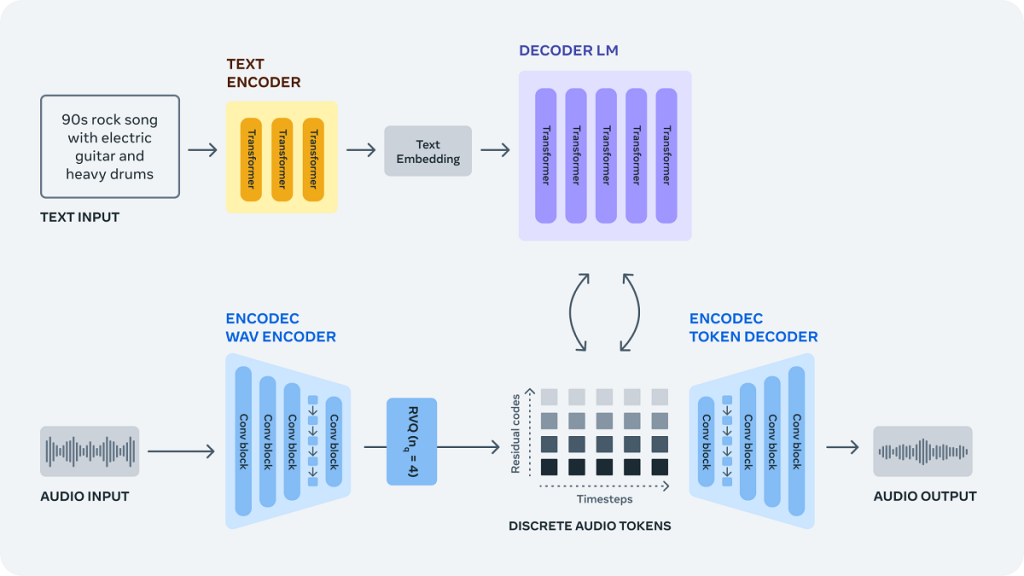
Meta has announced that its audio-generating AI will be open-source and available to all. With AudioCraft, musicians and game developers can easily create sound effects and soundtracks on a small budget. Meta describes AudioCraft as a simple framework for generating high-quality music and audio. Users give the AI text prompts that it uses to create sound. Before using the AI, however, it must be trained on raw audio signals.
AudioCraft is made up of three models, MusicGen, EnCodec and AudioGen. AudioGen generates sound effects, while MusicGen generates music tracks. Meta recently released a new version of its EnCodec decoder, which allows users to create higher-quality music with fewer artefacts. Additionally, the metaverse contender released its pre-trained AudioGen model and all the AudioCraft model weights and code for research purposes.
“The models are available for research purposes and to further people’s understanding of the technology,” states Meta in a blog post. “We’re excited to give researchers and practitioners access so they can train their own models with their own datasets for the first time and help advance the state of the art.”
Meta states that AudioCraft simplifies the design of audio-generating AI models. The Facebook owner aims to empower users to create their own models through the release of the generative AI model’s code. The AudioCraft suite allows users to generate sound and music and compress audio all within one space. According to Meta, users can quickly adapt and extend the models to suit their needs.
Meta Is Researching Ways to Advance AudioCraft
Meta is continuing research to further advance generative AI audio models. Specifically, Meta will look into better controllability of audio within generative AI models and various condition methods.
Meta says that the dataset its audio-generating AI was trained on is primarily Western-style music, while the models only work with audio-text pairs with text and metadata written in English. The company hopes that in releasing AudioCraft’s code, other researchers can introduce the AI model to different languages and styles of music.
The blog post says, “We believe the simple approach we developed to successfully generate robust, coherent and high-quality audio samples will have a meaningful impact on the development of advanced human-computer interaction models considering auditory and multi-modal interfaces. And we can’t wait to see what people create with it.”