





















A new AI system dubbed ‘Student of Games’ (SoG), has been developed by researchers from EquiLibre Technologies, Sony AI, Amii, and Midjourney in collaboration with Google’s DeepMind project. SoG marks a move toward achieving artificial general intelligence.
The new AI system combines directed search, self-play learning, and game-theoretic reasoning, making it a versatile algorithm applicable in diverse settings. By demonstrating remarkable performance in both perfect and imperfect information games, SoG excels in chess, Go, heads-up no-limit Texas hold ’em poker, and Scotland Yard.
Fusing GT-CFR and sound self-play
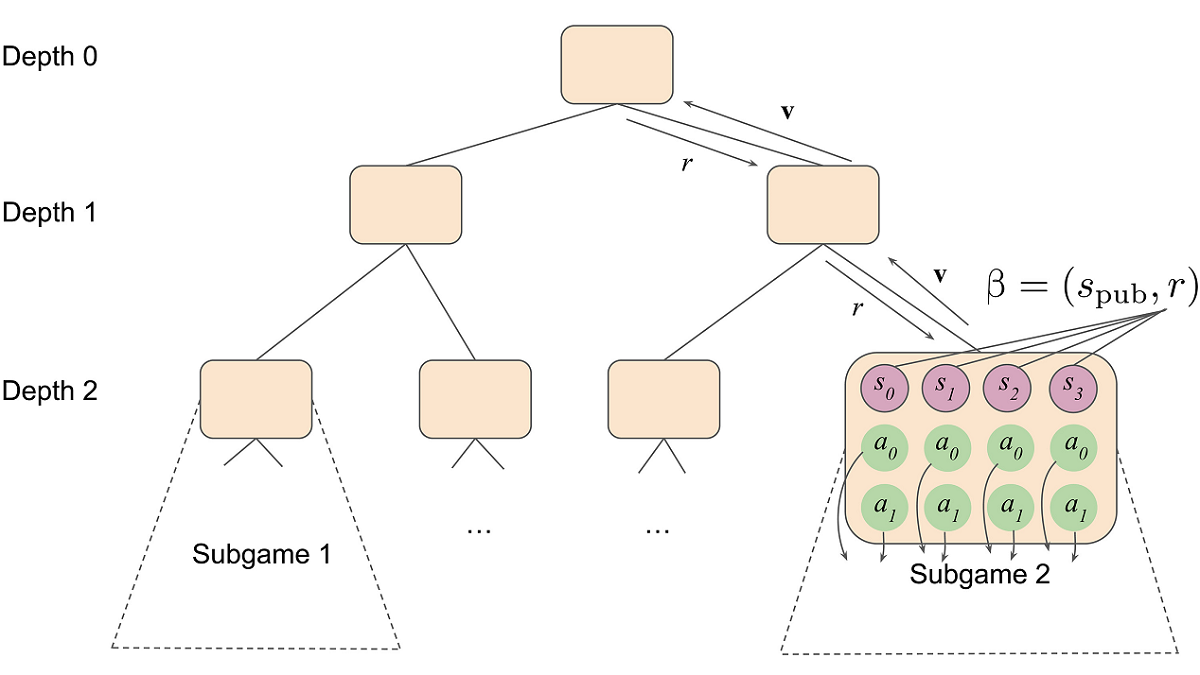
SoG’s approach integrates growing-tree counterfactual regret minimisation (GT-CFR) and sound self-play, creating a powerful algorithm for optimal and suboptimal information games. The use of GT-CFR also enables the non-uniform construction of subgames, emphasising crucial future states, while sound self-play trains value-and-policy networks based on game results and recursive sub-searches.
The algorithm’s effectiveness lies in its ability to adapt and refine strategies as computational resources improve. Empirical evidence, especially in Leduc poker, showcases SoG’s capability to generate better minimax-optimal techniques with increased search efforts, distinguishing it from pure reinforcement learning systems lacking search components.
Enhanced strategies
SoG’s method involves acoustic self-play, where players use GT-CFR search coupled with counterfactual value and policy networks (CVPNs) to produce policies for the current state, enhancing decision-making. GT-CFR iterations involve regret updating and expansion phases, updating the current public tree’s cumulative regret during regret updating and adding new general forms during expansion.
Training data for value and policy networks is generated through self-play, utilising search queries and full-game trajectories. The value network is updated based on counterfactual value targets derived from search queries, while the policy network is adjusted using targets from full-game trajectories.
Limitations and challenges
Despite its successes, SoG has some limitations, including potential improvements in handling vast action spaces and exploring generative models for world-state sampling. Achieving peak performance in challenging domains often requires substantial computational resources, prompting ongoing exploration of resource-efficient alternatives.
SoG’s ability to teach itself and excel in various games positions it as a versatile and promising AI system. Beating rivals and humans in Go, chess, Scotland Yard, and poker reflects its adaptability and potential for widespread applications. As AI continues to advance, SoG represents a step closer to realising artificial general intelligence capable of mastering an array of tasks previously deemed challenging for machines.
You can read the full paper here.
Isa Muhammad is a writer and video game journalist covering many aspects of entertainment media including the film industry. He's steadily writing his way to the sharp end of journalism and enjoys staying informed. If he's not reading, playing video games or catching up on his favourite TV series, then he's probably writing about them.