





















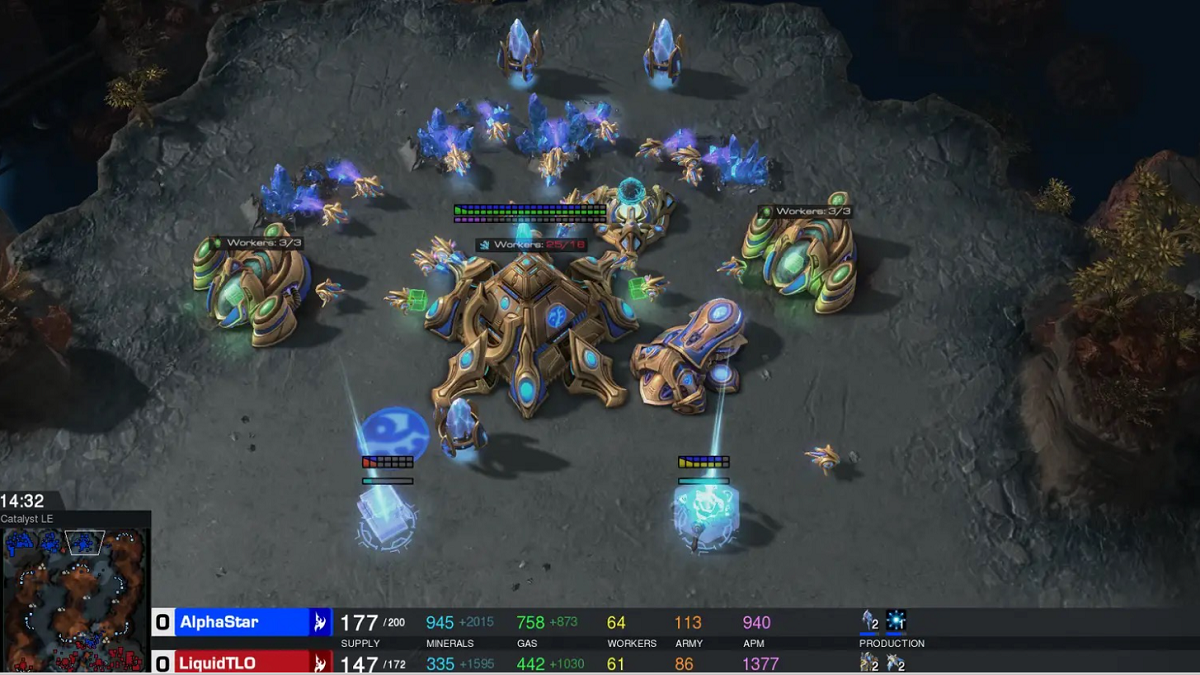
Real-time strategy game StarCraft has posed a significant challenge for AI research and is considered a, ‘Grand Challenge’. The game’s complex gameplay has pushed the limits of AI techniques, forcing innovative approaches to navigate its intricacy.
Researchers at Google DeepMind have now introduced AlphaStar Unplugged in a new paper, which has now become the first player to defeat a skilled StarCraft player. AlphaStar’s mastery of StarCraft II‘s gameplay is attributed to its deep neural network, which was trained through a combination of supervised learning and reinforcement learning on unprocessed game data.
Unlike previous AI successes in video games such as Atari, Mario, Quake III Arena Capture the Flag, and Dota 2, which heavily relied on online reinforcement learning (RL) techniques, often with modified game rules, enhancements to player abilities, or simplified maps, the intricate nature of StarCraft has presented a significant challenge for AI approaches.
Leveraging data sets
However, AlphaStar employs a vast dataset of replays from human players in StarCraft II. This framework allows for agent training and evaluation to be conducted without the need for direct interaction with the game environment.
StarCraft II is already a challenging game for offline reinforcement learning algorithms because of its partial observability, stochasticity, and multi-agent dynamics. These challenges make it an ideal testing ground for pushing the boundaries of offline RL algorithm capabilities.
The foundation of AlphaStar Unplugged is built on several notable contributions that create a demanding offline RL benchmark including:
- Using a fixed dataset and defined rules in the training setup to ensure fair comparisons between methods.
- A new set of evaluation metrics is introduced to accurately measure the performance of the agent.
- A variety of baseline agents that have been fine-tuned are offered as starting points for experimentation.
- The researchers provide a finely-tuned behaviour cloning agent that serves as a basis for all agents described in the paper.
New training methodologies
The AlphaStar Unplugged architecture provides a suite of reference agents for benchmarking and evaluating offline RL algorithms in StarCraft II. The game’s API provides a rich set of inputs, including vectors, units, and feature planes, which can be used to represent the game state.
The experimental results emphasise the impressive accomplishment of offline RL algorithms, showcasing a 90% win rate against the previously leading AlphaStar Supervised agent.
The introduction of DeepMind’s AlphaStar Unplugged sets an unprecedented benchmark that pushes the limits of offline reinforcement learning. By harnessing the complex game dynamics of StarCraft II, this benchmark establishes a foundation for enhanced training methodologies and performance metrics in the field of RL research.
Isa Muhammad is a writer and video game journalist covering many aspects of entertainment media including the film industry. He's steadily writing his way to the sharp end of journalism and enjoys staying informed. If he's not reading, playing video games or catching up on his favourite TV series, then he's probably writing about them.
