






















In its mission to democratise image segmentation by introducing a new task, dataset, and model, Meta AI has introduced its Segment Anything Model (SAM).
According to the Facebook parent company, “We are releasing both our general Segment Anything Model (SAM) and our Segment Anything 1-Billion mask dataset (SA-1B), the largest ever segmentation dataset, to enable a broad set of applications and foster further research into foundation models for computer vision.”
Meta AI also says that it is making the SA-1B dataset available for research purposes while the Segment Anything Model is available, “Under a permissive open license (Apache 2.0).”
The core of the project according to Meta is to reduce the need for, “Task-specific modeling expertise, training compute, and custom data annotation for image segmentation.”
“To realize this vision, our goal was to build a foundation model for image segmentation: a promptable model that is trained on diverse data and that can adapt to specific tasks, analogous to how prompting is used in natural language processing models,” said Meta.
Meta also adds that the segmentation data it needs to train such models isn’t currently available online or elsewhere. Segment Anything will allow the social media company to, “Simultaneously develop a general, promptable segmentation model and use it to create a segmentation dataset of unprecedented scale.”
Utilising ‘Segment Anything’ in different sectors
Meta has also revealed that SAM could be used to power applications in various domains that require finding and segmenting any object in any image. “For the AI research community and others, SAM could become a component in larger AI systems for more general multimodal understanding of the world, for example, understanding both the visual and text content of a webpage.”
“In the AR/VR domain, SAM could enable selecting an object based on a user’s gaze and then ‘lifting’ it into 3D… For content creators, SAM can improve creative applications such as extracting image regions for collages or video editing.”
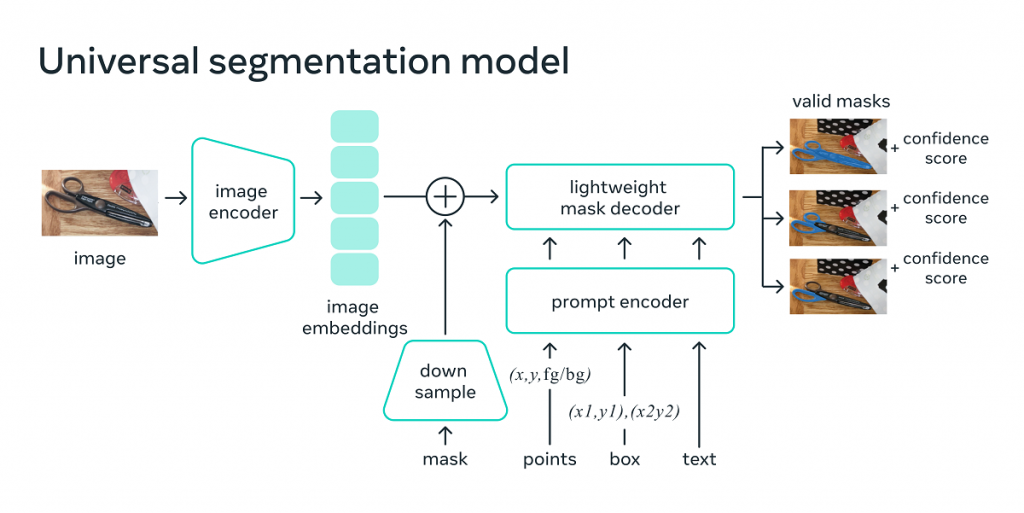
So far, there’s been two categories of methods available for solving segmentation issues: interactive segmentation and automatic segmentation. The former approach permits the segmentation of any object category and relies on human guidance to refine a mask iteratively.
Automatic segmentation, however, allows for the segmentation of predefined objects like cats or even chairs but requires a sufficient amount of manually annotated objects to be trained.
Meta’s SAM represents a synthesis of these two approaches by being a single model that can effectively handle both interactive and automatic segmentation tasks. The model’s promptable interface allows for versatility in its usage, making it suitable for a wide range of segmentation tasks by engineering the right prompt for the model, such as clicks, boxes, or text.
“And as we look ahead, we see tighter coupling between understanding images at the pixel level and higher-level semantic understanding of visual content, unlocking even more powerful AI systems,” said Meta.